Optimizing the order of aggregation pipelines
MongoDB does have a query optimizer, and in most cases it’s effective at picking the best of multiple possible plans. However it’s worth remembering that in the case of the aggregate function the sequence in which various steps are executed is completely under your control. The optimizer won’t reorder steps into the optimal sequence to get you out of trouble.
Optimizing the order of steps probably comes mainly to reducing the amount of data in the pipeline as early as possible – this reduces the amount of work that has to be done by each successive step. The corollary is that steps that perfom a lot of work on data should be placed after any filter steps.
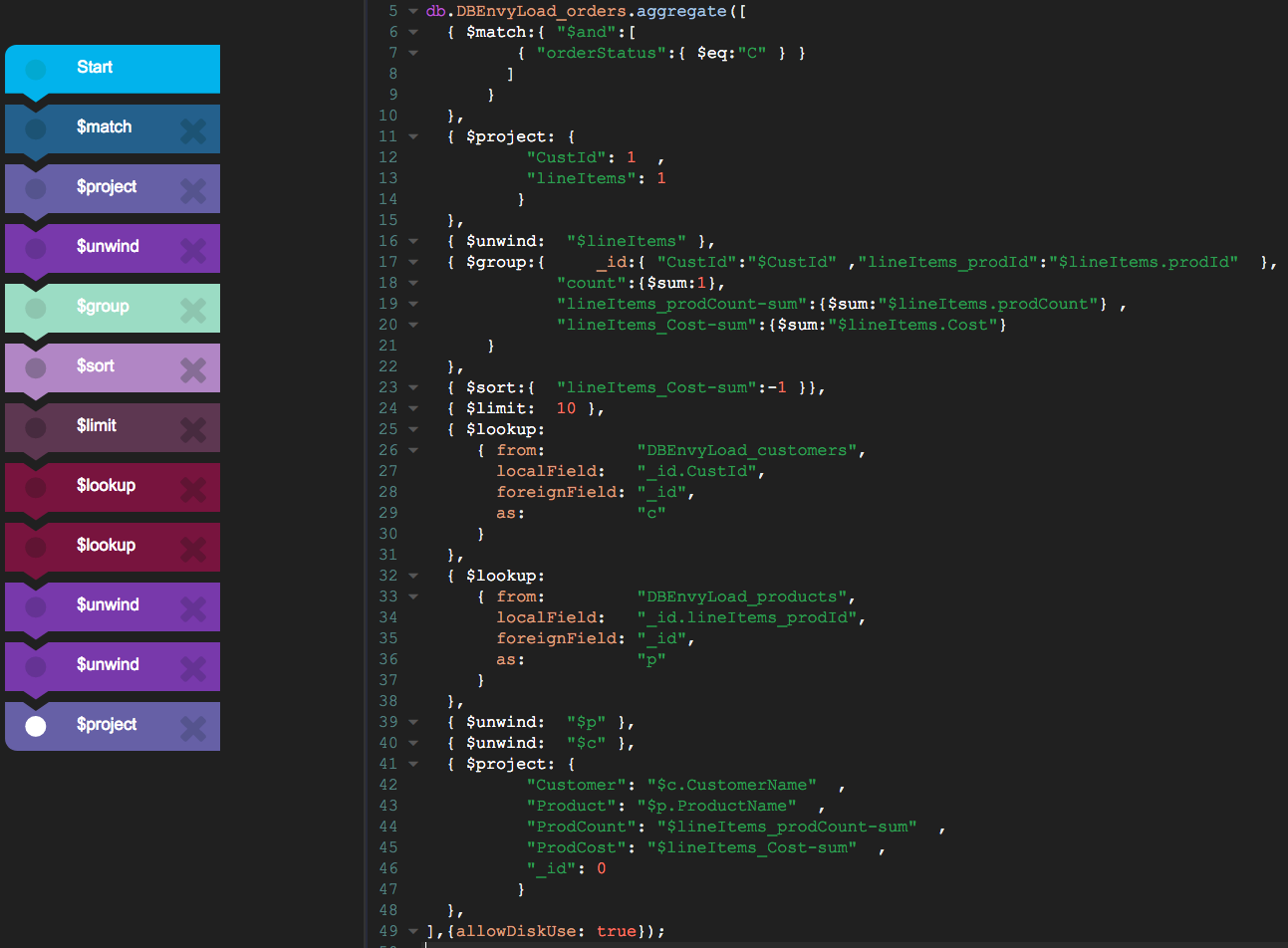
Nowhere is this more important that in $lookup steps. Since $lookup steps perform a separate collection lookup – hopefully using an index – we should make sure we delay them until all data has been filtered. Consider this aggregation function, which generates a “top 10” list of product purchases by customer:
var output=db.orders.aggregate([
{$sample:{size:sampleSize}},
{$match:{orderStatus:"C"}},
{$project:{CustId:1,lineItems:1}},
{$unwind:"$lineItems"},
{$group:{_id:{ CustId:"$CustId",ProdId:"$lineItems.prodId"},
"prodCount":{$sum:"$lineItems.prodCount"},
"prodCost":{$sum:"$lineItems.Cost"}}},
{$sort:{prodCost:-1}},
{$limit:10},
{$lookup:{
from: "customers",
as: "c",
localField: "_id.CustId",
foreignField: "_id"
} },
{$lookup:{
from: "products",
as: "p",
localField: "_id.ProdId",
foreignField: "_id"
}},
{$unwind:"$p"},{$unwind:"$c"}, //Get rid of single element arrays
{$project:{"Customer":"$c.CustomerName","Product":"$p.ProductName",
prodCount:1,prodCost:1,_id:0}}
]);
Lines 11-22 perform lookups on the customers and products collection to get customer and product names.
We could have done these lookups much earlier in the pipeline. So for instance, this code returns the exact same results, but does the lookup a little earlier in the sequence:
var output=db.orders.aggregate([
{$sample:{size:sampleSize}},
{$match:{orderStatus:"C"}},
{$project:{CustId:1,lineItems:1}},
{$unwind:"$lineItems"},
{$group:{_id:{ CustId:"$CustId",ProdId:"$lineItems.prodId"},
"prodCount":{$sum:"$lineItems.prodCount"},
"prodCost":{$sum:"$lineItems.Cost"}}},
{$lookup:{
from: "customers",
as: "c",
localField: "_id.CustId",
foreignField: "_id"
}},
{$lookup:{
from: "products",
as: "p",
localField: "_id.ProdId",
foreignField: "_id"
}},
{$sort:{prodCost:-1}},
{$limit:10},
{$unwind:"$p"},{$unwind:"$c"}, //Get rid of single element arrays
{$project:{"Customer":"$c.CustomerName","Product":"$p.ProductName",
prodCount:1,prodCost:1,_id:0}}
]);
The difference in performance is striking. By moving the $lookup a few lines earlier, we have created a much less scalable solution:

When the $lookups are before the $limit step, we have to perform as many lookups as there are matching rows. When we move after the $limit we only have to perform 10. It’s an obvious but important optimization.
Unlike a SQL query optimizer, MongoDB will not perform any of these optimizations for you - you have to use “the optimizer between your ears”.
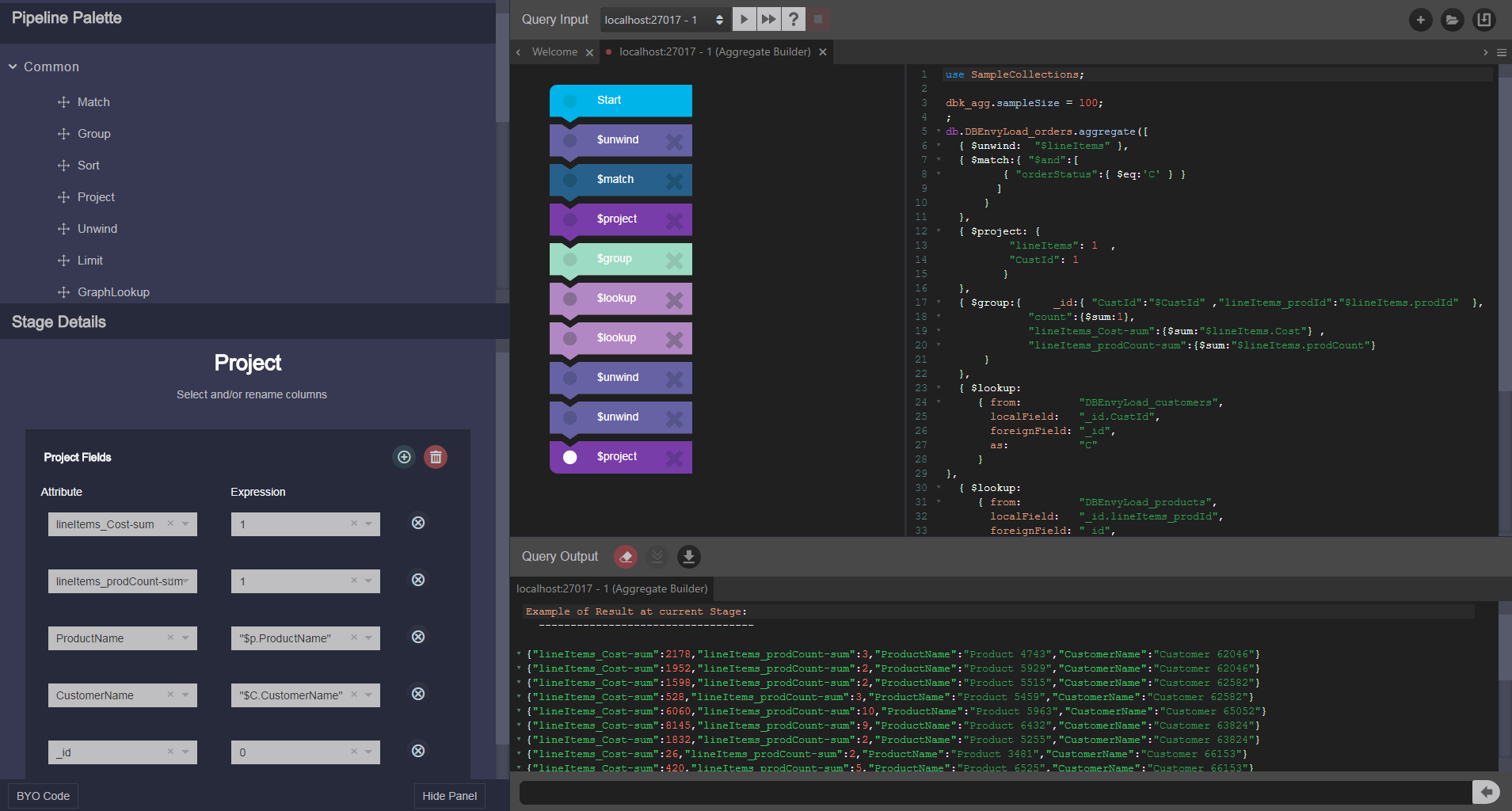
Using the dbKoda aggregation builder, we can simply drag and drop the steps into whatever order we like. Providing the new order makes sense, dbKoda will rewrite the aggregation code for you. The dbKoda aggregation editor is the fastest way to create aggregration pipelines. And - like the rest of dbKoda - it is free and open source.