Getting started with MongoDB explain()
For almost all operations, there will be more than one way for MongoDB to retrieve the documents required. When MongoDB parses a statement, it must decide which approach will be fastest. The process of determining this “optimal” path to the data is referred to as query optimisation.
Basics of query optimization
For instance, consider the following query:
db.mycustomers.find(
{
FirstName: "RUTH",
LastName: "MARTINEZ",
Phone: 496523103
},
{ Address: 1, dob: 1 }
).
sort({ dob: 1 });
There are indexes on FirstName, LastName, Phone and dob. This gives MongoDB the following choices for resolving the query:
- Scan the entire collection looking for documents that match all the condition, then sort those documents by
dob - Use the Index on
FirstNameto find all the “RUTH”s, then filter out those documents based onLastNameandPhone, then sort the remainder ondob. - Use the Index on
LastNameto find all the “MARTINEZ”s, then filter out those documents based onFirstNameandPhone, then sort the remainder ondob. - Use the Index on
Phoneto find all documents with a matching phone number. Then eliminate any who are not RUTH MARTINEZ, then sort by dob. - Use the Index on
dobto sort the documents indoborder, and eliminate and documents that don’t match the query criteria.
The MongoDB optimizer decides which of these approaches to take. The explain() method reveals the query optimizer’s decision and - in some cases - lets you examine it’s reasoning.
Getting started with explain()
To See the explain output we use the explain() method of the collection object and pass a find(),update(), insert(), drop() or aggregate() to that method. For instance to explain the query above we could do this:
var explainDoc=db.mycustomers.explain().
find(
{
FirstName: "RUTH",
LastName: "MARTINEZ",
Phone: 496523103
},
{ Address: 1, dob: 1 }
).
The resulting explainDoc object is a cursor that returns a JSON document (after you call the next() method). The bit that is most important initially is the winningPlan section, which we can extract like this:
mongo> var explainJson = explainDoc.next();
mongo> printjson(explainJson.queryPlanner.winningPlan);
{
"stage" : "PROJECTION",
"transformBy" : {
"Address" : 1,
"dob" : 1
},
"inputStage" : {
"stage" : "SORT",
"sortPattern" : {
"dob" : 1
},
"inputStage" : {
"stage" : "SORT_KEY_GENERATOR",
"inputStage" : {
"stage" : "FETCH",
"filter" : {
"$and" : [
{
"FirstName" : {
"$eq" : "RUTH"
}
},
{
"LastName" : {
"$eq" : "MARTINEZ"
}
}
]
},
"inputStage" : {
// I removed some stuff here
]
}
}
}
}
}
}
It’s still pretty complex - and I removed some stuff to simplify it. However, you see it contains multiple stages of query execution with the input to each stage (eg the previous step) nested as inputStage. So have to read the JSON from the inside-out to get the plan. If you want, you can use this simple function to print out the steps in the order then are execution (this works for most plans, but not for explains from sharded collections):
mongo> function quick_explain(explainPlan) {
var stepNo = 1;
var printInputStage = function(step) {
if ("inputStage" in step) {
printInputStage(step.inputStage);
}
if ("inputStages" in step) {
step.inputStages.forEach(function(inputStage){
printInputStage(inputStage);
});
}
if ("indexName" in step) {
print(stepNo++, step.stage, step.indexName);
} else {
print(stepNo++, step.stage);
}
};
printInputStage(explainPlan);
}
dbKoda>quick_explain(explainJson.queryPlanner.winningPlan);
1 IXSCAN Phone_1
2 FETCH
3 SORT_KEY_GENERATOR
4 SORT
5 PROJECTION
dbKoda>
This script prints the execution plan in a very succinct format. Here’s an explanation of each step:
| Step | Explanation |
|---|---|
IXSCAN Phone_1 : |
Used the index to find documents with a matching value for Phone |
FETCH : |
Filtered out documents based on the Firstname and Lastname criteria |
SORT_KEY_GENERATOR : |
Emitted dob attributes for the next step |
SORT : |
sorted documents on the dob |
PROJECTION : |
Pushed address and dob into the output stream |
There are a lot of different types of steps in explain output and there is no one place I know of to find all of the step descriptions (though https://docs.mongodb.com/manual/reference/explain-results/ is a good start). Probably the three most interesting steps are:
COLLSCAN - which means the document was scanned without an index.
IXSCAN - the use of an index to find documents
SORT - the sorting of documents without an index.
Alternate plans
Explain can tell you not just which plan was used, but which other plans were rejected. The rejected plans can be found within the array rejectedPlans within the queryPlanner section. So here is an example of looking at a rejected plan:
dbKoda>quick_explain(explainJson.queryPlanner.rejectedPlans[1])
1 IXSCAN LastName_1
2 IXSCAN Phone_1
3 AND_SORTED
4 FETCH
5 SORT_KEY_GENERATOR
6 SORT
7 PROJECTION
Execution Statistics
If you pass the argument executionStats to explain, then explain will actually run the statement and report on the performance of each step in the plan:
var explainDoc = db.mycustomers.
explain('executionStats').
find(
{FirstName: "RUTH",
LastName: "MARTINEZ",
Phone: 496523103},
{ Address: 1, dob: 1 }
).sort({ dob: 1 });
var explainJson = explainDoc.next();
The execution statistics are included in the executionStages section of the resulting plan document:
dbKoda>explainJson.executionStats
{
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 2,
"totalKeysExamined" : 1,
"totalDocsExamined" : 1,
"executionStages" : {
"stage" : "PROJECTION",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 1,
"needTime" : 3,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"transformBy" : {
"Address" : 1,
"dob" : 1
},
"inputStage" : {
"stage" : "SORT",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 1,
"needTime" : 3,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"invalidates" : 0,
"sortPattern" : {
"dob" : 1
},
"memUsage" : 6293,
// I removed some stuff here
}}
}
The executionSteps subdocument contains overall execution statistics - such as executionTimeMillis - as well as an annotated execution plan in the executionStages document. executionStages is structured just like winningPlan, but it has statistics for each step. There are a lot of statistics, but perhaps the most significant ones are:
-
executionTimeMillisEstimateEstimate of the ms spent in each step. -
keysExaminedNumber of index keys read -
docsExaminedNumber of documents read by this step
It’s hard to read the execution stats - so I wrote this little function to print out the steps and key statistics in the same format as the quick_explain script:
function executionStats(execStats) {
var stepNo = 1;
print('\n');
var printSpaces = function(n) {
var s = '';
for (var i = 1; i < n; i++) {
s += ' ';
}
return s;
};
var printInputStage = function(step, depth) {
if ('inputStage' in step) {
printInputStage(step.inputStage, depth + 1);
}
if ('inputStages' in step) {
step.inputStages.forEach(function(inputStage) {
printInputStage(inputStage, depth + 1);
});
}
var extraData = '(';
if ('indexName' in step) extraData += ' ' + step.indexName;
if ('executionTimeMillisEstimate' in step) {
extraData += ' ms:' + step.executionTimeMillisEstimate;
}
if ('keysExamined' in step)
extraData += ' keys:' + step.keysExamined;
if ('docsExamined' in step)
extraData += ' docs:' + step.docsExamined;
extraData += ')';
print(stepNo++, printSpaces(depth), step.stage, extraData);
};
printInputStage(execStats.executionStages, 1);
print(
'\nTotals: ms:',
execStats.executionTimeMillis,
' keys:',
execStats.totalKeysExamined,
' Docs:',
execStats.totalDocsExamined
);
}
We’ll use this function in the next section to tune a MongoDB query.
Using explain to tune a query
Now that we’ve learned how to use explain, let’s run through a short example of how to use it to tune a query. Here is the explain for the query we want to tune:
var explainDoc = db. messages.explain("executionStats").
find({ $and: [{ mailbox: "baughman-d" },
{ subFolder: "enron_power/interviews" }]},
{ "headers.Subject": 1 } )
.sort({ "headers.Date": 1 });
Let’s use our little function to extract the executionStats:
dbKoda>var explainJson = explainDoc.next();
dbKoda>executionStats(explainJson.executionStats);
1 COLLSCAN ( ms:902 docs:120477)
2 SORT_KEY_GENERATOR ( ms:902)
3 SORT ( ms:902)
4 PROJECTION ( ms:902)
Totals: ms: 883 keys: 0 Docs: 120477
The COLLSCAN step comes first, and examines 120,477 documents. It only takes 902ms, but still maybe we can do better. There’s also a SORT in there, and I’d like to see if I can avoid the sort using an index. So let’s create an index that has the attributes from the filter clause (mailbox and subfolder), and the attribute from the sort operation (headers.Date). Here’s the new index:
db.messages.createIndex({mailbox:1,subFolder:1,
"headers.Date":1},
{name:"myNewIndex"})
Now when we issue explain('executionStats') our output looks like this:
dbKoda>executionStats(explainJson.executionStats);
1 IXSCAN ( myNewIndex ms:0 keys:42)
2 FETCH ( ms:0 docs:42)
3 PROJECTION ( ms:0)
Totals: ms: 1 keys: 42 Docs: 42
Using the index the query now returns almost instantaneously and the number of documents (keys) examined has reduced to 42. We’ve reduced the amount of data accessed by 97% and improved execution time by infinity :-). Note also that there is no longer and SORT step - MongoDB was able to use the index to return documents in sorted order without an explicit sort.
Conclusion
Explain() is one of the key “tools of the trade” that anyone wanting to tune MongoDB queries should learn. We have just scratched the surface in this blog post but this introduction should at least give you enough information to confidently examine the plans for your MongoDB queries. In a subsequent post, I’ll talk about how to gather cached execution plans and how to use explain() in conjunction with the profiler.
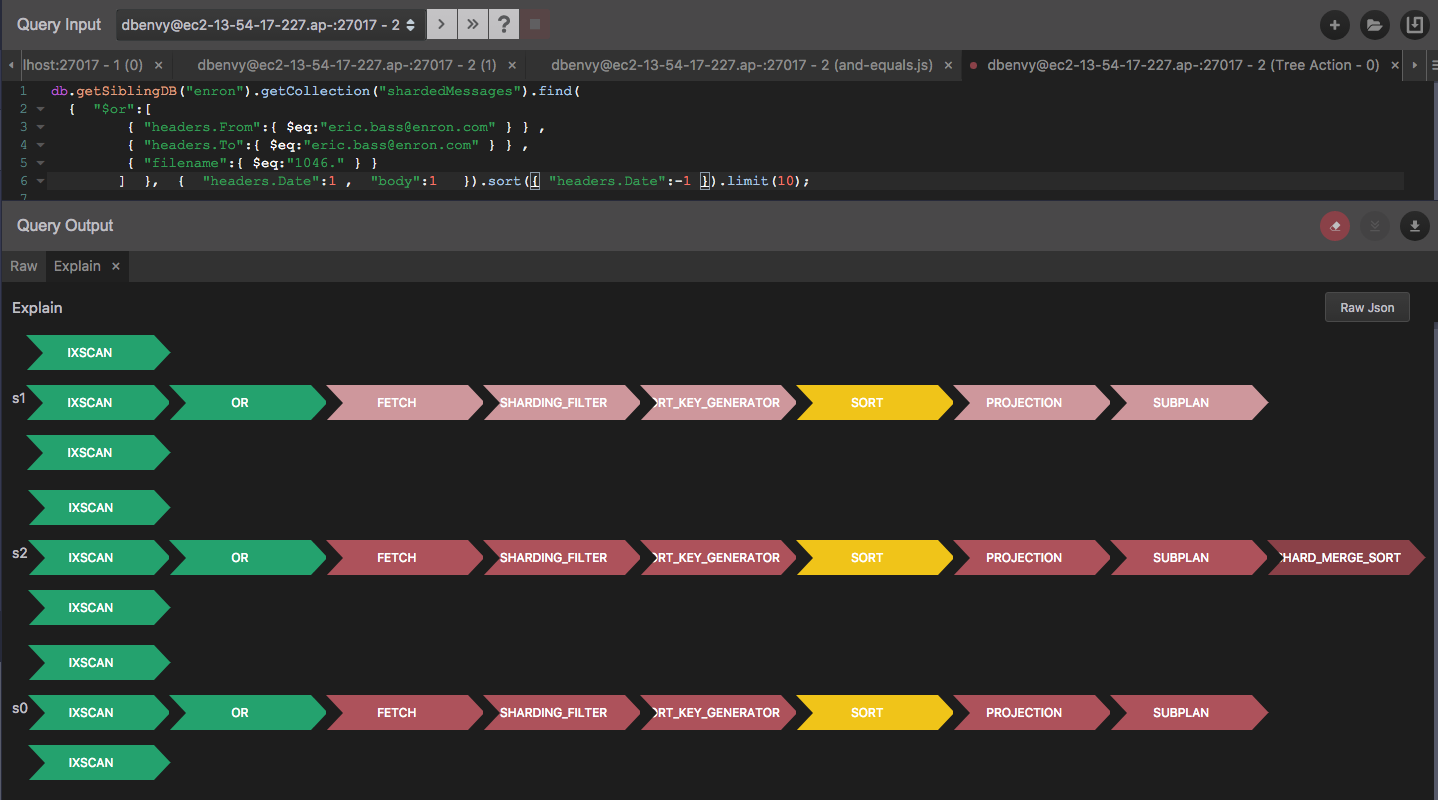
Using explain in dbKoda
dbKoda is our open source IDE for MongoDb. It contains lots of great stuff, but most relevantly to this article, it contains a graphical explain plan display that clearly illustrates the execution plan for your query and described how each step is executed in plain english. Get dbKoda for free at http://dbkoda.com/download.
